class: center, middle, inverse, title-slide .title[ # Estatística & Estatística e Informática ] .subtitle[ ## Distribuição de Frequência ] .author[ ### Alan Rodrigo Panosso <a href="mailto:alan.panosso@unesp.br" class="email">alan.panosso@unesp.br</a> ] .institute[ ### Departamento Ciências Exatas ] .date[ ### 12 e 13 de março de 2026 ] --- class: middle, center, inverse ## SOMATÓRIA --- **Conjunto de dados**: Nessa notação, a variável numérica de interesse (altura, idade ou peso, por exemplo) será representada pelas letras maiúsculas do nosso alfaveto latino `\(X\)`, `\(Y\)`, `\(Z.\)` O conjunto de dados terá o tamanho `\(n\)`, que representa o número de elementos que ele contém. Em outras palavras, `\(n\)` representa o tamanho da amostra, o **número de observações** ou de **realizações** da variável. Os valores específicos assumidos por tais variáveis serão representados pelas letras minúsculas `\(x\)`, `\(y\)` e `\(z\)`, respectivamente, seguidas de um índice `\(i\)` que representa a posição daquele valor específico dentro do conjunto de dados. Assim, para distinguir um valor do outro, utilizamos esse índice `\(i\)`, que pode ser entendido como uma *variável auxiliar*, utilizada para contagem, que se inicia na posição `\(1\)` e termina na última posição, `\(n\)`, abrangendo todo o seu conjunto de dados. Assim temos: `\(\text{Altura}: X = \{x_1, x_2, ..., x_n\}, \text{ com }i = 1,2,..,n.\)` `\(\text{Idade}: Y = \{y_1, y_2, ..., y_n\}, (i = 1,2,..,n).\)` `\(\text{Peso}: Z = \{z_1, z_2, ..., z_n\}, (i = 1,2,..,n).\)` Nessa notação um valor típico da variável *Altura*, será designado por `\(x_i\)` e o valor final por `\(x_n\)`. --- **Somatória**: Ao realizar a análise de uma variável quantitativa é necessário somar todos os seus valores. Essa operação é frenquetemente utilizada na estatística, assim, utiliza-se uma notação compacta para representar a soma de todos os valores de uma variável de interesse. Portanto, dado a variável `\(X\)` a soma de todos seus valores será notada pela letra grega *sigma* maiúscula `\(\Sigma\)`: Dados `\(X = \{x_1, x_2, x_3, x_4, x_5\}\)`, a soma desses `\(5\)` valores: `\(x_1 + x_2 + x_3 + x_4 + x_5\)` será representada pela notação: `\(\sum\limits_{i=1}^{n}{x_i}\)` ou `\(\sum_{i=1}^{n}{x_i}\)` onde `\(i\)` atua como o índice, ou seja, a cada *iteração* ele muda e representa um dos `\(5\)` valores de `\(X\)`. --- #### Utilização da Função Frequência da Calculadora Científica: Limpe a memória da calculadora e entre com os dados `\(\{18, 18, 20, 20, 18, 19, 19, 20, 18, 20\}\)`. Organizando-os em tabela de frequência, temos: Idade| `\(n_i\)` :---|:---: 18 | 4 19 | 2 20 | 4 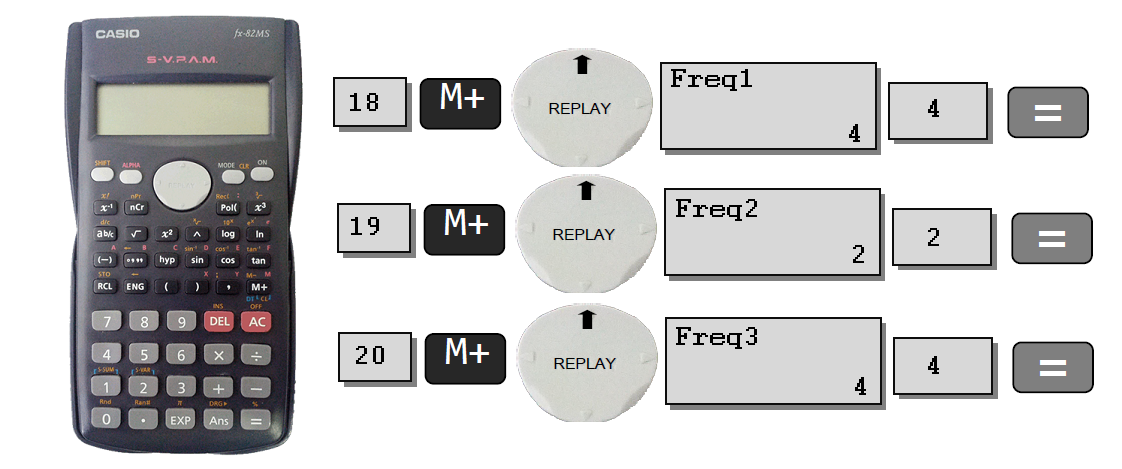 --- ### Exemplo Dado duas variáveis `\(X = \{3,0,5,9,7\}\)` e `\(Y = \{2,3,9,1,2\}\)`, calcular: Qual a somatória do produto entre as variáveis `\(X\)` e `\(Y\)`: Dado `\(X = \{3,0,5,9,7\}\)` e `\(Y = \{2,3,9,1,2\}\)`, calcular: `\(\sum\limits_{i=1}^{n}{x_iy_i}\)` `\(\sum\limits_{i=1}^{n}{x_i y_i}= x_1 \cdot y_1 + x_2 \cdot y_2 + x_3 \cdot y_3 + x_4 \cdot y_4 + x_5 \cdot y_5\)` `\(\sum\limits_{i=1}^{n}{x_i y_i}= 3 \cdot (2) + 0\cdot( 3) + 5 \cdot(9) + 9 \cdot(1) + 7 \cdot(2)\)` `\(\sum\limits_{i=1}^{n}{x_i y_i}= 6 + 0 + 45 + 9 + 14 = 74\)` --- **Propriedades da Somatória** **i)** A somatória de uma constante `\((k)\)` é igual ao produto `\(n \cdot k\)`. `\(\begin{aligned} \sum \limits_{i=1}^{n}{k} &= k + k + \cdots + k \\ &= n \cdot k\end{aligned}\)` --- **ii)** A somatória dos produtos de uma constante `\(k\)` e uma variável `\(X\)` é igual ao produto da constante pela soma dos valores da variável. `\(\begin{aligned} \sum\limits_{i=1}^{n}{k \cdot x_i} &= k \cdot x_1 + k \cdot x_2 + \cdots + k \cdot x_n \\ &= k \cdot (x_1 + x_2+ \cdots + x_n) \\ &= k \sum\limits_{i=1}^{n}{x_i} \end{aligned}\)` --- **iii)** A somatória da soma de duas variáveis é igual à adição das somatórias individuais dessas duas variáveis: `\(\begin{aligned} \sum\limits_{i=1}^{n}{(x_i+y_i)} &= (x_1 + y_1 + x_2 + y_2 + \cdots + x_n + y_n) \\ &= (x_1 + x_2 + \cdots + x_n) + (y_1 + y_2 + \cdots + y_n) \\ &= \sum\limits_{i=1}^{n}{x_i} + \sum\limits_{i=1}^{n}{y_i} \end{aligned}\)` --- ## Exercícios 1) Calcular: `\(\sum\limits_{i=1}^{n}{(k \cdot x_i+k)}=?\)` 2) Dado a média sendo: `\(\bar{x} = \frac{\sum\limits_{i=1}^{n}{x_i}}{n}\)` Provar que: `\(\sum\limits_{i=1}^{n}{(x_i-\bar{x})}=0\)` --- ### Resposta 1) `\(\sum\limits_{i=1}^{n}{(k \cdot x_i+k)}=?\)` `\(\sum\limits_{i=1}^{n}{(k \cdot x_i+k)} = \sum\limits_{i=1}^{n}{ k \cdot x_i} + \sum\limits_{i=1}^{n}k\)` `\(\sum\limits_{i=1}^{n}{(k \cdot x_i+k)} = \sum\limits_{i=1}^{n}{k \cdot x_i} + \sum\limits_{i=1}^{n}k\)` `\(\sum\limits_{i=1}^{n}{(k \cdot x_i+k)} = k \cdot \sum\limits_{i=1}^{n}{x_i} + n \cdot k\)` --- ### Resposta 2) Dado: `\(\bar{x} = \frac{\sum\limits_{i=1}^{n}{x_i}}{n}\)`, `\(\sum\limits_{i=1}^{n}{(x_i-\bar{x})}= \sum\limits_{i=1}^{n}{x_i}-\sum\limits_{i=1}^{n}{\bar{x}}\)` `\(\sum\limits_{i=1}^{n}{(x_i-\bar{x})}= \sum\limits_{i=1}^{n}{x_i}-n \cdot {\bar{x}}\)` `\(\sum\limits_{i=1}^{n}{(x_i-\bar{x})}= \sum\limits_{i=1}^{n}{x_i}-n \cdot \frac{\sum\limits_{i=1}^{n}{x_i}}{n}\)` `\(\sum\limits_{i=1}^{n}{(x_i-\bar{x})}= \sum\limits_{i=1}^{n}{x_i}-\sum\limits_{i=1}^{n}{x_i} =0\)` --- class: middle, center, inverse # Distribuição de Frequência --- ### Distribuição de frequência de uma variável Quando analisamos uma variável aleatória (qualitativa ou quantitativa), deve-se conhecer a distribuição de frequência dessa variável por meio de suas possíveis realizações (observações). Assim, o objetivo dessa aula será apresentar as principais formas e visualização gráfica de variáveis quali e quantitativas. **Exemplo:** Considerando os [dados-turmas-2026.xlsx](https://raw.githubusercontent.com/arpanosso/estatinfo/refs/heads/master/data/dados-turmas-2026.xlsx) amostrados das turmas de Estatísticas temos: Podemos organiza-los da seguinte forma: [dados-turmas-2026.pdf](https://raw.githubusercontent.com/arpanosso/estatinfo/refs/heads/master/docs/dados-turmas-2026.pdf) 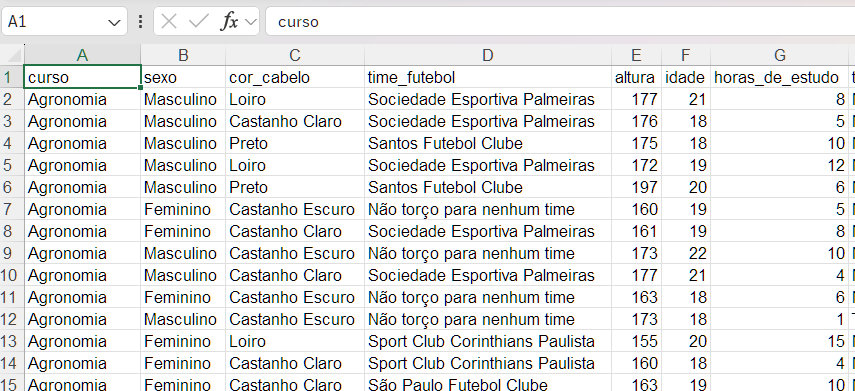 --- **Tamanho da População `\((N)\)`** O tamanho da população `\(N\)` é o número total dos elementos alvos da pesquisa. Muitas vezes não conhecemos esse valor. $$ N = \text{tamanho da população (desconhecido)} $$ Em nosso exemplo, poderíamos entender como `\(N\)` o número de todos os alunos de graduação da Unesp. $$ N = 35188 $$ Maiores informações, acesso o Painel [Somos UNESP](https://app.powerbi.com/view?r=eyJrIjoiMzM4YjhhOGMtMDQyNS00Y2VhLTk2ZDAtZThkMTU3ZWVhNTE0IiwidCI6ImZlODc4N2JjLWM5MTQtNDY2NS04NTQ3LTI2OGUxNWNiMGQ5YSJ9) 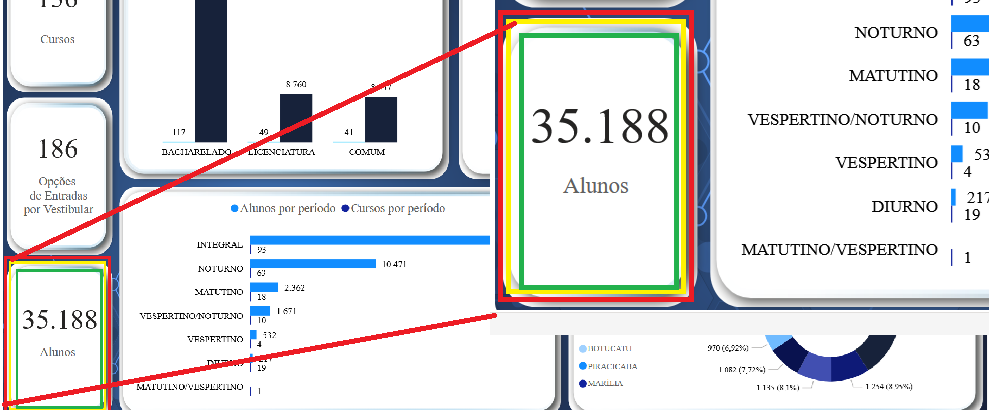 --- **Tamanho da amostra `\((n)\)`** É o número total de registros de sua base de dados, ou seja o número total de elementos amostrados da população. Em nosso exemplo é o número de alunos que responderam ao formulário. $$ n =91 $$ --- ### Variável sexo (qualitativa nominal) Agora Construir uma tabela de frequências para a variável `sexo` contendo as frequências absolutas `\((n_i)\)`, as frequências relativas `\((f_i)\)` e a porcentagem de frequência `\((perc)\)` para as categorias `\(Feminino\)` e `\(Masculino\)`. Agora podemos definir o número de categorias dessa variável como `\(k\)`, ou seja, nesse caso: $$ k = 2$$ --- ### Frequência Absoluta `\((n_i)\)` É definida como o número de observações no conjunto de dados pertencentes à uma categoria/classe da variável em estudo. Então, consideramos `\(n_1\)` para sexo `\(Feminino\)` e `\(n_2\)` para sexo `\(Masculino\)`, temos: `\(n_1 = 33\)` `\(n_2 = 58\)` --- Observe que a somatória da frequência absoluta das classes `\((k)\)` da variável cetegória é igual a `\(n\)`. $$ \sum \limits_{i=1}^{k}{n_i} = n $$ sendo `\(k\)` é o número de categorias. $$ `\begin{aligned} \sum_{i=1}^{k} n_i &= n_1 + n_2 \\ &= 33 + 58 \\ &= 91 \end{aligned}` $$ --- **Frequência Relativa `\((f_i)\)`** É definida como a proporção de cada categoria em relação ao **Total de observações** `\((n)\)`, ou seja: $$ f_i = \frac{n_i}{n} $$ Portanto temos que: - Para categoria `\(Feminino\)`: $$ f_1 = \frac{33}{91}=0{,}3626 $$ - Para categoria `\(Masculino\)` $$ f_2 = \frac{58}{91}=0{,}6373 $$ --- Observe que a somatória das frequências relativas sempre será igual a `\(1\)`: $$ `\begin{aligned} \sum_{i=1}^{k} f_i &= f_1 + f_2 \\ &= 0{,}3626 + 0{,}6373 \\ &= 1 \end{aligned}` $$ sendo `\(k\)`, o número de categorias da variável `sexo`. --- **Porcentagem de frequência `\((perc \text{, %})\)`** Definida como o resultado da multiplicação da frequência relativa (proporção) por `\(100\)`. `$$perc_1 = f_1 \times 100 = 0{,}3626 \times 100 = 36{,}26\% \\ perc_2 = f_2 \times 100 = 0{,}6373 \times 100 = 63{,}73\%$$` De maneira análoga, a somatória das porcentagens sempre será igual a `\(100\)`: $$ `\begin{aligned} \sum_{i=1}^{k} perc_i &= perc_1 + perc_2 \\ &= 36{,}26 + 63{,}73 \\ &= 100 \end{aligned}` $$ --- Assim, temos a tabela de frequência da variávies **sexo (Qualitativa)** |sexo | ni| fi| perc| |:---------|--:|---------:|--------:| |Feminino | 33| 0.3626374| 36.26374| |Masculino | 58| 0.6373626| 63.73626| A partir das tabelas de frequência, poderemos criar representações gráficas que nos auxiliarão na apresentação e interpretação do comportamento dos dados. Essa etapa é a denominada de **Apresentação - Visualização de Dados**. --- class: middle, center, inverse # APRESENTAÇÃO - VISUALIZAÇÃO DE DADOS ## (Variáveis Qualitativas) --- ## Apresentação - Visualização dos dados Os tipos de gráficos variam de acordo com o tipo de variável, geralmente, para as **variáveis qualitativas** utilizamos os gráficos de: - Barras; - Colunas; - Setores (Pizza). --- ### Gráfico de Colunas para variável sexo <img src="Aula03_files/figure-html/plot1-1.png" style="display: block; margin: auto;" /> --- ### Gráfico de Barras para variável sexo Semelhante ao gráfico de colunas, contudo, com as barras na horizontal, facilita a leitura do nome das categorias. <img src="Aula03_files/figure-html/plot2-1.png" style="display: block; margin: auto;" /> --- ### Gráfico de Setores para variável sexo <img src="Aula03_files/figure-html/plot3-1.png" style="display: block; margin: auto;" /> --- ## Tabela de Frequência para a variável Cor de cabelo Construir a tabela de frequência para variável `cor_cabelo`. -- |cor_cabelo | ni| fi| perc| |:---------------|--:|---------:|--------:| |Castanho Claro | 16| 0.1758242| 17.58242| |Castanho Escuro | 44| 0.4835165| 48.35165| |Loiro | 12| 0.1318681| 13.18681| |Preto | 19| 0.2087912| 20.87912| --- ### Gráfico de Colunas para Cor de cabelo <img src="Aula03_files/figure-html/plot4-1.png" style="display: block; margin: auto;" /> --- ### Gráfico de Barras para Cor de cabelo <img src="Aula03_files/figure-html/plot5-1.png" style="display: block; margin: auto;" /> --- ### Gráfico de Setores para cor_cabelo <img src="Aula03_files/figure-html/plot6-1.png" style="display: block; margin: auto;" /> --- ## Tabela de Frequência e Visualização dos dados **Variável Altura (Quantitativa Contínua)** Quando a variável quantitativa, construímos a tabela de frequência, podemos utilizar intervalos de classes e os principais gráficos são: - histograma; - boxplot; - Distribuição acumulada Devemos, inicialmente construir a tabela de frequência da variável `altura`. Porém, os valores de uma variável contínua não se repetem, mesmo que isso aparentemente ocorra na base de dados. Em teoria suas observações podem assumir qualquer valor dentro da reta dos números `\(\mathbb{R}\)`, portanto, ao mensurar uma variável contínua, obtém-se apenas uma aproximação de seu verdadeiro valor dada pelo instrumento de medida. --- ### Tabela de frequência Para exemplificar, vamos criar uma tabela de frequência com `\(k = 5\)` classes de alturas. |classes_altura | ni| fi| perc| |:--------------|--:|---------:|---------:| |(155,163] | 18| 0.1978022| 19.780220| |(163,172] | 20| 0.2197802| 21.978022| |(172,180] | 37| 0.4065934| 40.659341| |(180,189] | 11| 0.1208791| 12.087912| |(189,197] | 5| 0.0549451| 5.494505| Agora vamos construir o histograma --- ### Amplitude Total `\(\Delta\)` Vamos iniciar com a Amplitude total `\((\Delta)\)`, definida como a diferença entre o valor máximo menos o valor mínimo da variável. `$$\Delta = Máximo - Mínimo$$` Para os dados de altura temos, `\(\Delta = 197-155 = 42 \;\text{cm}\)` --- ### Número de intervalos de classes `\((k)\)` Definiremos `\(k\)` como sendo o número de **sub-intervalos** da Amplitude Total. Uma boa representação apresenta um `\(k\)`. **NUNCA** inferior a `\(5\)` ou superior a `\(15\)`, pois com um pequeno número de classes, perde-se informação, e com um grande número de classes, o objetivo de resumir os dados fica prejudicado. -- ### Amplitude de classe `\((\Delta_i)\)` É o tamanho de cada um dos `\(k=5\)` sub-intervalos, dado pela amplitude total dividida pelo número de intervalos. `$$\Delta_i = \frac{\Delta}{k}$$` Para os dados de altura: `$$\Delta_i = \frac{\Delta}{k} = \frac{42}{5} = 8{,}4 \;cm$$` --- Assim, temos que cada um dos `\(5\)` intervalos terá uma amplitude de `\(8{,}4\)` cm. Ou seja, o cálculo dos limites das classes é feito a partir da adição ao valor Mínimo o valor de `\(\Delta_i\)` um número de `\(k\)` vezes. LI = Limite Inferior da Classe e LS = limite Superior da Classe - Classe 1: LI = `\(Mínimo = 155\)` e LS = `\(Mínimo \times \Delta_i = 155 \times (8{,}4) = 163{,}4\)` - Classe 2: LI = LS anterior = `\(163{,}4\)` e LS = `\(Mínimo \times 2\Delta_i = 155 \times 2\dot(8{,}4) = 171{,}8\)` - Classe 3: LI = `\(171{,}8\)` LS = `\(Mínimo \times 3\Delta_i = 155 \times 3\dot(8{,}4) = 180{,}2\)` - Classe 4: LI = `\(180{,}2\)` e LS = `\(Mínimo \times 4\Delta_i = 155 \times 4\dot(8{,}4) = 188{,}6\)` - Classe 5: LI = `\(188{,}6\)` e LS = `\(Mínimo \times 2\Delta_i = 155 \times 2\dot(8{,}4) = 197\)` --- ### Gráfico histograma (frequências absolutas) A partir da tabela anterior, pode-se construir o gráfico de frequência de cada classe de valor de altura, denominado **Histograma**. <img src="Aula03_files/figure-html/plot10-1.png" style="display: block; margin: auto;" /> --- ## Gráfico histograma (frequências relativas) Ao longo de nosso curso, vamos estudar que a frequência relativa `\(f_i\)` é uma estimativa empírica da probabilidade `\(P(X=x_i)\)`, assim é interessante que a área total da figura do histograma seja igual a `\(1\)`, correspondendo à soma total das frequências relativas `\(( f_i )\)`. Então, para construção do histograma, sugere-se usar no eixo das ordenadas os valores de `\(fi / \Delta_i\)` (denominado densidade de frequência), ou seja, da medida que indica qual a concentração por unidade da variável. --- <img src="Aula03_files/figure-html/plot11-1.png" style="display: block; margin: auto;" /> --- ## Densidade de frequência `\((d_i)\)` Agora vamos atualizar a tabela com o valor de densidade de frequência, dado por: `$$d_i=\frac{f_i}{\Delta_i}$$` |classes_altura | ni| fi| perc| di| |:--------------|--:|---------:|---------:|---------:| |(155,163] | 18| 0.1978022| 19.780220| 0.0235479| |(163,172] | 20| 0.2197802| 21.978022| 0.0261643| |(172,180] | 37| 0.4065934| 40.659341| 0.0484040| |(180,189] | 11| 0.1208791| 12.087912| 0.0143904| |(189,197] | 5| 0.0549451| 5.494505| 0.0065411| --- ## Medidas Acumuladas As medidas acumuladas são interessantes para compor algumas vizualizações: `\(N_i\)`: Frequência Absoluta Acumulada. `\(F_i\)`: Frequência Relativa Acumulada. `\(Perc\)`: Porcentagem de Frequência Acumulada. #### Tabela de Frequência para Altura |classes_altura | ni| fi| perc| di| Ni| Fi| Perc| |:--------------|--:|---------:|---------:|---------:|--:|---------:|---------:| |(155,163] | 18| 0.1978022| 19.780220| 0.0235479| 18| 0.1978022| 19.78022| |(163,172] | 20| 0.2197802| 21.978022| 0.0261643| 38| 0.4175824| 41.75824| |(172,180] | 37| 0.4065934| 40.659341| 0.0484040| 75| 0.8241758| 82.41758| |(180,189] | 11| 0.1208791| 12.087912| 0.0143904| 86| 0.9450549| 94.50549| |(189,197] | 5| 0.0549451| 5.494505| 0.0065411| 91| 1.0000000| 100.00000| --- ## Função de Distribuição Acumulada A função de distribuição acumulada descreve como probabilidades são associadas aos valores ou aos intervalos de valores de uma variável aleatória. Em outras palavras, ela representa a probabilidade de uma variável aleatória ser menor ou igual a um valor real qualquer `\(x\)`. $$ F(x) = P(X \leq x) \in [0,1]. $$ Para uma variável aleatória contínua (`altura`): `$$\int \limits_{- \infty }^x f(x_i) dx$$` --- <img src="Aula03_files/figure-html/plot13-1.png" style="display: block; margin: auto;" /> --- # FIM <!-- ## Histograma e Polígono de Frequência --> <!-- Obtemos o polígono de frequências unindo por uma poligonal (segmentos de retas) os pontos correspondentes às frequências, das classes, centradas nos pontos médios de cada classe. --> <!-- Para se obter as interseções do polígono com o eixo horizontal, cria-se em cada extremo do histograma uma classe com frequência nula. --> <!-- ```{r,plot12,eval=FALSE, echo=FALSE} --> <!-- dados_turmas_2026 |> --> <!-- ggplot(aes(x=altura, y=..count..))+ #<< --> <!-- geom_histogram(breaks = limites, --> <!-- color="black", --> <!-- fill="gray") + --> <!-- geom_freqpoly(breaks=limites,color="red") #<< --> <!-- ``` --> <!-- --- --> <!-- ## Histograma e Estimativas de densidade suavizadas --> <!-- Calcula e desenha a estimativa da densidade, que é uma versão suavizada do histograma. Esta é uma alternativa útil para dados contínuos que vêm de uma distribuição suave subjacente. --> <!-- ```{r,plot12_1,eval=FALSE} --> <!-- dados_turmas_2026 |> --> <!-- ggplot(aes(x=altura,y=..density..))+ #<< --> <!-- geom_histogram(breaks = limites, --> <!-- color="black", --> <!-- fill="white") + --> <!-- geom_density(color="red", --> <!-- fill="green", --> <!-- alpha=0.05) #<< --> <!-- ``` --> <!-- - Observe que o histograma foi construído com as frequências absolutas `\((n_i)\)`, ou seja, `y=..density..`. Utilizamos a função `geom_density()`. --> <!-- - O argumento `alpha=0.05` controla a transparência do preenchimento. --> <!-- --- --> <!-- ```{r,plot12_1,echo=FALSE} --> <!-- ``` --> <!-- --- --> <!-- class: middle, center, inverse --> <!-- ## Prática para Casa: Instalação de Pacotes no R --> <!--  --> <!-- [Link do Video](https://drive.google.com/drive/u/0/folders/1O-sGhicXs6unUY_y1JW8yKSHm76VVMCX) --> <!-- --- --> <!-- **Pacote em R** --> <!-- Um pacote é uma coleção de funções, exemplos e documentação. A funcionalidade de um pacote é frequentemente focada em uma metodologia estatística especial" (**Everitt & Hothorn**). --> <!--  --> <!-- Pacotes no R são coleções de funções, exemplos e documentações, que devem ser previamente instalados e alocados no ambiente pela função `library`. --> <!-- --- --> <!-- ## Pacotes básicos --> <!-- Liste os pacotes carregados no ambiente com: --> <!-- ```{r} --> <!-- (.packages()) --> <!-- ``` --> <!-- O retorno da função é uma lista de nomes, `caracteres` (ou `strings`), na forma de um *objeto* denominado **vetor**. Observe que cada pacote (elemento) é referenciado dentro do vetor por um índice, um número inteiro `\([\;i\;]\)` apresentado entre colchetes **[i]**. --> <!-- Carregue um pacote chamando a função `library`. --> <!-- ```{r,message=FALSE} --> <!-- library(MASS) --> <!-- ``` --> <!-- --- --> <!-- Agora, liste novamente os pacotes e observe a diferença no retorno da função. --> <!-- ```{r} --> <!-- (.packages()) --> <!-- ``` --> <!-- Observe que o pacote `MASS` agora está no ambiente de trabalho. --> <!-- --- --> <!-- ### Instalando pacotes --> <!-- Para a realização de procedimentos estatístico e manipulação de arquivos durante o curso, serão necessários vários pacotes que não fazem parte do `base` do R, que deverão ser instalados. --> <!-- **Utilizando a opção** `Packages\Install\nome do pacote` --> <!-- ```{r echo=FALSE, fig.cap="",fig.align='center',out.width = "450px"} --> <!-- knitr::include_graphics("img/install_pac.png") --> <!-- ``` --> <!-- Instale os pacotes: --> <!-- * `tidyverse` --> <!-- * `agricolae` --> <!-- --- --> <!-- Os pacotes também podem ser instalados a partir das linhas de comandos: --> <!-- ```{r,eval=FALSE} --> <!-- install.packages("tidyverse") --> <!-- install.packages("agricolae") --> <!-- ``` --> <!-- Agora podemos carregar esses pacotes em nosso ambiente de trabalho. --> <!-- ```{r,message=FALSE,error=FALSE} --> <!-- library(tidyverse) --> <!-- library(agricolae) --> <!-- ``` --> <!-- Vamos agora criar uma "Pipe Line" para visualização de um banco de dados --> <!-- ```{r,message=FALSE,error=FALSE} --> <!-- mtcars |> --> <!-- glimpse() --> <!-- ``` --> <!-- O simbolo para operação de arquivos de dados é o pipe `|>` que pode ser criado a partir do atalho `CTRL + SHIFT + M` --> <!-- --- --> <!-- ## Carregando os dados no R --> <!-- Para carregar o banco de dados da turma no R, siga os passos: --> <!-- 1.Faça o Download dos [dados_turmas.xlsx](https://arpanosso.github.io/estatinfo/data/dados_turmas.xlsx). --> <!-- 2.Salve em uma pasta `data` dentro de um projeto do R previamente criado. --> <!-- <img src="https://arpanosso.github.io/estatinfo/slides/img/download_.png" style=" display: block; margin-left: auto; margin-right: auto;width: 85%"></img> --> <!-- --- --> <!-- 3.Na aba **Environment** do RStudio selecione **Import Dataset/From Excel...** como apresentado abaixo. --> <!-- <img src="https://arpanosso.github.io/estatinfo/slides/img/importa_r.png" style=" display: block; margin-left: auto; margin-right: auto;width: 95%"></img> ] --> <!-- --- --> <!-- 4.Selecione **Browse** (destacado em vermelho no canto direito superior). --> <!-- <img src="https://arpanosso.github.io/estatinfo/slides/img/importa_r1.png" style=" display: block; margin-left: auto; margin-right: auto;width: 95%"></img> --> <!-- --- --> <!-- 5.Na próxima janela busque o arquivo da base de dados **dados_turmas.xlsx** que salvamos na pasta "*data"*, selecione o arquivo e clique em **Open**. --> <!-- <img src="https://arpanosso.github.io/estatinfo/slides/img/importa_r2.png" style=" display: block; margin-left: auto; margin-right: auto;width: 95%"></img> --> <!-- --- --> <!-- 6.Na janela serão apresentados os dados, **NÃO CLIQUE EM IMPORT**, ao invés disso, **selecione e copie o código** para a importação dos dados. Após isso **CLIQUE EM CANCEL**. --> <!-- <img src="https://arpanosso.github.io/estatinfo/slides/img/importa_r3.png" style=" display: block; margin-left: auto; margin-right: auto;width: 95%"></img> --> <!-- --- --> <!-- 7.Cole o código no seu script do R e o execute. Os dados serão salvos no objeto `dados_turmas`. Se necessário, instale o pacote `readxl` com as opções da aba **Packages/Install** ou com o comando `install.packages("readxl")`. --> <!-- ```{r, eval=FALSE} --> <!-- library(readxl) --> <!-- dados_turmas <- read_excel("data/dados_turmas.xlsx") --> <!-- View(dados_turmas) --> <!-- ``` --> <!-- ```{r,echo=FALSE} --> <!-- `|>` <- magrittr::`|>` --> <!-- library(dplyr) --> <!-- library(tidyr) --> <!-- library(ggplot2) --> <!-- library(readxl) --> <!-- dados_turmas <- read_excel("../data/dados_turmas.xlsx") --> <!-- ``` --> <!-- <img src="https://arpanosso.github.io/estatinfo/slides/img/importa_r4.png" style=" display: block; margin-left: auto; margin-right: auto;width: 60%"></img> -->